
Multi-token prediction in LLMs
Facebook's results, multi-token vs next-token, and self-speculative decoding


In this post:
This post dives into what multi-token prediction is, how it differs from the standard next-token prediction mechanism used in most LLMs, how it’s used in self-speculative decoding, and my thoughts around the topic.
Better & Faster Large Language Models via Multi-token Prediction [Facebook]
Paper Highlights
Next-token prediction
Multi-token prediction
Self-speculative decoding
Results
Future work
My thoughts
🧠 Better & Faster Large Language Models via Multi-token Prediction
Facebook experimented with adjusting a model to predict the next N tokens (rather than only the next 1 token) for text generation AI tasks and published their findings earlier this year. They achieved this by modifying the cross-entropy loss function. Their results show an increase in performance when larger LLMs are trained with multi-token prediction, as well as faster inference times when multiple heads are utilised. However, the benefits are not seen on smaller models, nor across all benchmarks.
Read the paper: https://arxiv.org/abs/2404.19737
Model code on HuggingFace: https://huggingface.co/facebook/multi-token-prediction
Abstract
Large language models … are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk. Considering multi-token prediction as an auxiliary training task, we measure improved downstream capabilities with no overhead in training time for both code and natural language models. The method is increasingly useful for larger model sizes... Gains are especially pronounced on generative benchmarks like coding… Experiments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3 times faster at inference, even with large batch sizes.
📝 Paper Highlights
They argued that multi-token prediction would “drive these models toward better sample efficiency.”
Multi-token prediction asks the model to predict the next N tokens simultaneously and in parallel. To do this, they modify the cross-entropy loss function to predict for the next N tokens.
Next-token prediction
Usually during language model training, the model is given a sequence of tokenised data, and for a position in the sequence asked to predict the next 1 token.
For a sequence A B C D, predict the next token (actual value: E)
To the predict this next token, the model predicts a probability distribution over all the possible next tokens (aka the model vocabulary).
So, a probability is assigned to every token in the models vocabulary that is it the next token
A: 0%, B: 0.05%, …, E: 61.5%, …
The token with the highest probability (the predicted token) is compared with the actual (true) next token (one-hot encoded vector of value 1) and the cross-entropy loss is calculated.
E had the highest probability, and is compared with the true value: E
The model’s goal is to minimise this cross-entropy loss by increasing the probability in the probability distribution of the correct next-token.
Multi-token prediction
They modify the above process to predict for the next N tokens by using N independent heads.
For example, consider a sequence of data: A B C D E F G, where N = 3.
Let’s say we’re up to the fifth position in the sequence (E). The model is passed everything before this point (A B C D) as the input context.
Head 1 considers A B C D and predicts the next 1 token as E
Head 2 considers A B C D and predicts the 2nd token to be F
Head 3 considers A B C D and predicts the 3rd token to be G
As you can see, each of the N heads sees the same input sequence.
This does mean Heads 2 and 3 are making predictions without knowing the tokens before the token they’re asked to predict (Head 2 doesn’t know the token before is E, and Head 3 doesn’t know the tokens before are E F).
The authors of this paper report that this multi-token prediction architecture has no increase in training time or memory overhead. They also make additional changes to the architecture to make it more memory efficient, which you can read about in the paper.
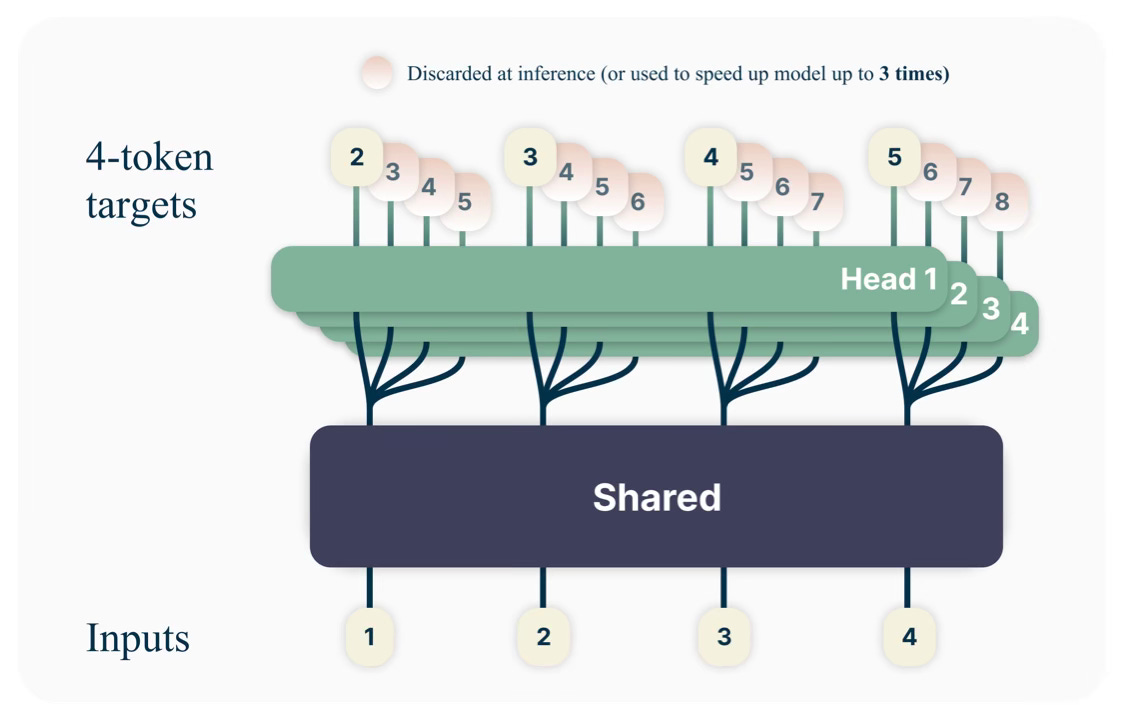
While providing multiple methods of utilising this proposed architecture, they recommend using it for model training, and then conducting inference with a vanilla next-token prediction head. They note that the additional heads can be used to speed up decoding during inference in a self-speculative decoding manner.
Self-speculative decoding
Self-speculative decoding is where the model predicts multiple tokens ahead in the sequence, and then compares these predictions against what the model would have predicted one token at a time.
For a sequence: A B C D E F G, where the model is given A B C D as input, it will self-speculatively predict E F G as the next multi-tokens.
The model will then go token-by-token and generate predictions for these same token positions (E, then F, then, G) and at each point compare if the token-by-token prediction is the same as the multi-token prediction.
If it is — great!
If it is not — the rest of the multi-token prediction is done away with, and token-by-token is used (or another method).
At first, this seemed to me like doing the same operation twice and to be honest I feel as though I’ll go down a long research rabbit hole to fully explain why it isn’t.
The broad reasoning I’ve found is that this token-by-token verification is less computationally intensive than generating predictions token-by-token, and that speculatively generating multiple tokens is also more efficient than generating them token-by-token (one forward pass vs multiple sequential forward passes to get the same result).
Results
They conducted seven large-scale experiments to evaluate multi-token prediction losses. Here are some of their main findings:
Multi-token prediction is most useful on larger models, and appears to scale in efficiency as models grow in parameter size. It leads to degraded performance on smaller language models.
Self-speculative decoding led to speeds up code-generation inference x3 on the 4-token trained 7B parameter model when compared with a standard token-by-token trained 7B parameter model.
They used a next-token prediction task at a byte-level to demonstrate that next-token prediction models focus on local patterns, whereas the multi-token prediction model performed remarkably better. In this instance, the input data is tokenised into bytes (for text, each letter is its own token).
Models pre-trained with multi-token prediction loss performed better than next-token models when fine-tuned. When the the 4-token prediction model was fine-tuned on a coding dataset — one model using the multiple heads for multi-token prediction during inference and another model with only the next-token prediction — it performed better than the standard next-token model (of the same 7B parameter size).
The use of the pre-trained multi-token prediction model being fine-tuned for next-token prediction performed best.
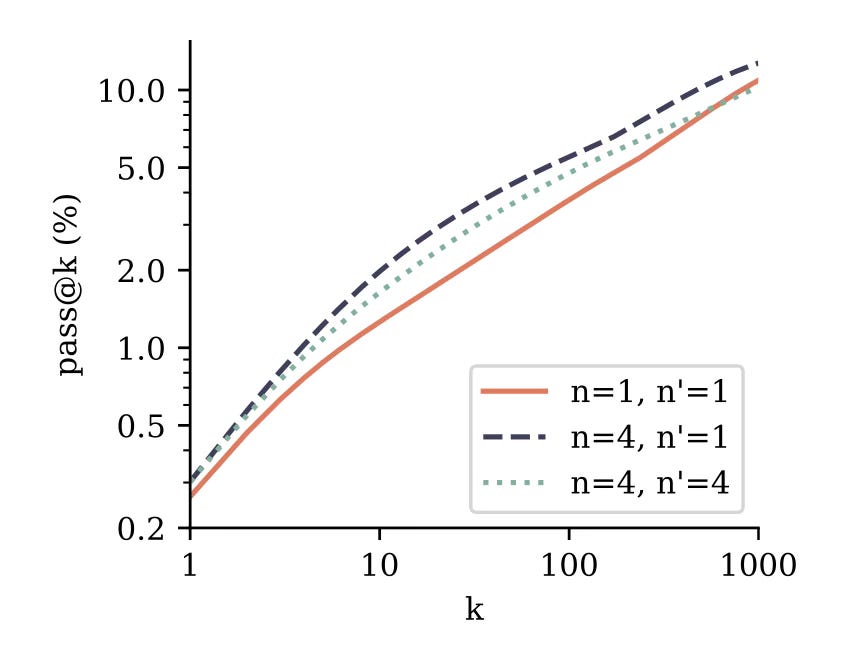
“Figure 4: Comparison of finetuning performance on CodeContests… Intriguingly, using next-token prediction finetuning on top of the 4-token prediction model appears to be the best method overall.“ The model was tested on Natural Language Processing benchmarks:
Multiple choice and likelihood benchmarks: the standard next-token model and 2-token model performed around the same. The 4-token model performed worse.
Summarisation: 2-token and 4-token performed better than next-token.
Natural language mathematics: 2-token does better than next-token. 4-token does considerably worse.
Future work
Methods of selecting N for multi-token prediction are to be investigated.
They note that the optimal vocabulary sizes for multi-token prediction models likely differ than those for next-token prediction models.
Thoughts
If you’ve read (or skimmed) my previous two posts, you’ll have seen I like to try out the models I read about in code for myself. However, as the most beneficial aspect of this multi-token prediction architecture is when it’s used on sufficiently large language models, there is little use in me attempting to force Google Colab to run it. At 7B parameters, I imagine it will infer in a similar timeframe as Gemma 2 (read about that here).
What intrigued me the most was the idea of multi-token prediction. It took some time for me to wrap my head around it, particularly regarding the benefit of asking the model to predict a tokens multiple places ahead without even guessing the tokens in-between. However, on reflection, it makes sense how this method of predicting could prove beneficial for some tasks, especially if those tokens in between are filler, I imagine.
A related work is Medusa. From a quick skim of the paper, it appears that Medusa takes an existing LLM (you provide) and adds additional heads to it which generate “multiple top predictions for its designated position”. These predictions are turned into candidates which are evaluated with the best selected as the output. This work proposes some interesting ideas similar to, but not the same as, those provided by Facebook’s multi-token paper. You can read the Medusa paper here: https://arxiv.org/pdf/2401.10774.
Thank you for reading!