


Gemma-2
Google's new "lightweight" open LLM model


In this post:
Gemma-2
Overview
Paper highlights
Gemma-2 vs my free computational resources 🥊
Challenges & troubleshooting
Comparing free cloud resources (Google Colab vs HuggingFace Spaces)
vCPU’s and GPU’s explained
Improvements to make
🔭 Gemma-2
Gemma-2 is a new lightweight and open model, boasting “state-of-the-art” performance. Two versions have so far been released, one with 9 billion parameters, and one with 27 billion parameters. A smaller, third version with 2 billion parameters is on the way.
Gemma-2 is capable of a variety of natural language processing tasks. Instruction fine-tuned versions have also been openly released (which allow interaction in a way akin to ChatGPT, Claude, and other instruction-tuned models).
Read Google’s introductory post: https://blog.google/technology/developers/google-gemma-2/
Read the HuggingFace overview post: https://huggingface.co/blog/gemma2
Read the paper: https://storage.googleapis.com/deepmind-media/gemma/gemma-2-report.pdf
Use the models: https://huggingface.co/collections/google/gemma-2-release-667d6600fd5220e7b967f315
Abstract
In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. The 9 billion and 27 billion parameter models are available today, with a 2 billion parameter model to be released shortly…The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3× bigger. We release all our models to the community.
📄 Paper Highlights
Gemma-2, like it’s predecessor Gemma, has a decoder only transformer model architecture (learn more about this architecture here)
Gemma-2 has deeper networks than Gemma
They used Knowledge Distillation to create the smaller models from a larger “teacher” model (learn more here)
They found:
Distilling a model of some size from a teacher model performed better than training a model of the same size from scratch.
A deeper models of some parameter size performed better than a wider model of the same parameter size. This difference in performance was small but consistent across benchmarks.
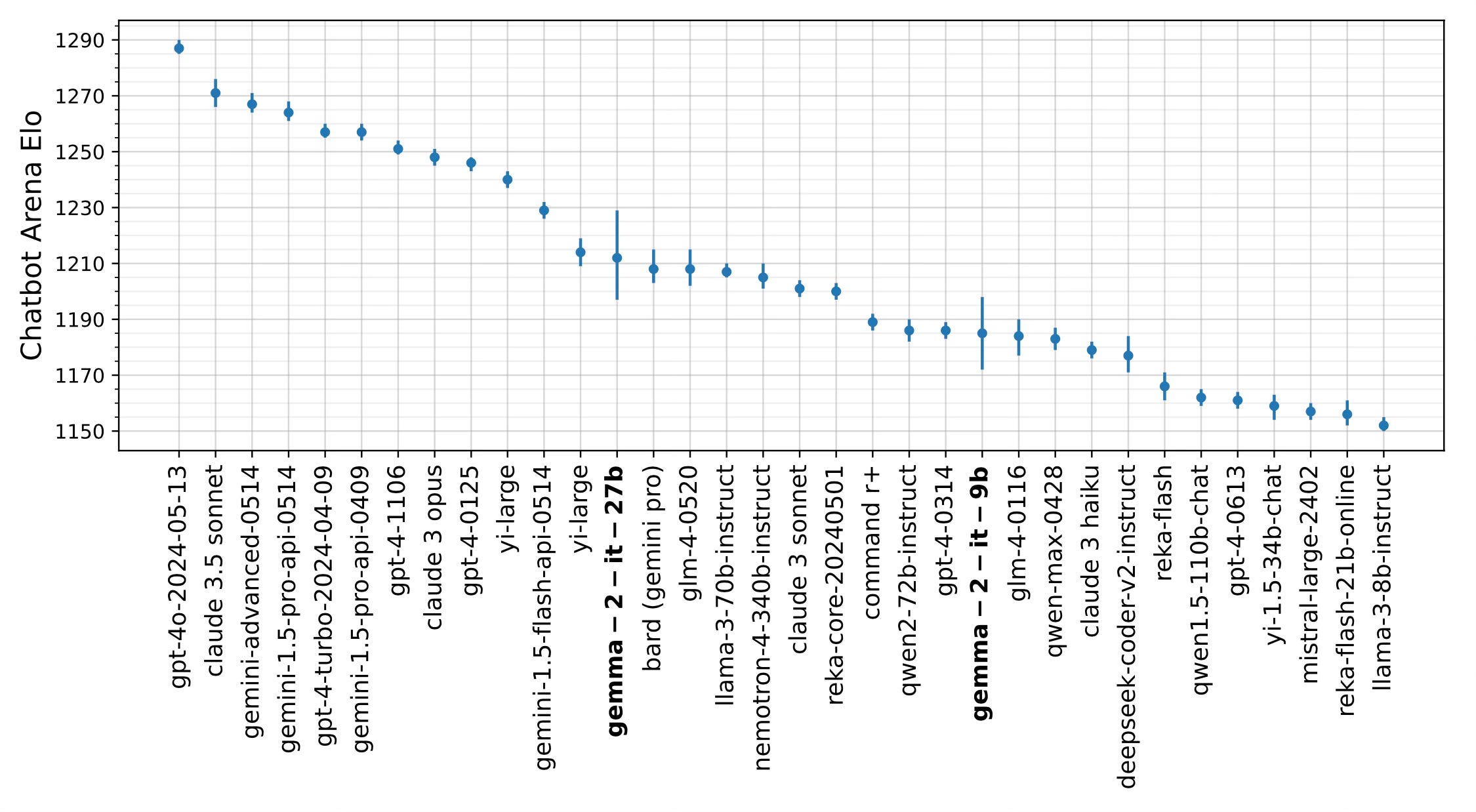
Thoughts
I would have liked additional extrapolations from them as to why knowledge distillation provided better results than normal training.
Knowledge distillation requires one sufficiently large model to be trained before additional smaller models can be created. If the performance of smaller models created in this way is truly better, then — unless this method of model creation is more computationally expensive and environmentally unfriendly — it looks like a smart direction to be moving in.
🤖 Gemma-2 chatbot
I’ve had a project idea floating around in my mind for a few weeks now. It involves finding a free, open LLM designed for “chatbot” behaviour.
Now, I could say my reason for choosing Gemma-2 to begin development of this project idea could be because I was impressed by the paper. But to be honest, I went to the trending models page of HuggingFace and recalled seeing Gemma-2 in a blog headline I’d scrolled past earlier in the day, so decided to use it.
Challenges
Alternative title: celine vs the conglomerate ai machines 🥊
The primary challenge I’ve encountered on my journey of utilising big, open LLMs is that of resources. Computational resources are small and memory is restricted within the free version of Google Colab (and even more-so in HuggingFace Spaces). Due to this, receiving a response from Gemma-2 takes multiple minutes (Google Colab) or is outside feasible time limits (HuggingFace Spaces) for my uses. Regardless, I set out to get something working with Gemma-2.
To perform inference (return a response), *large* LLMs require sufficiently large amounts of computational resources. The T4 GPU provided by Google Colab for free is typically enough for training and running inference on smaller ML models. However, in this instance, I found even the smallest Gemma-2 model currently available (9B) is still too large to easily run in Google Colab.
Troubleshooting I had to do:
I started by developing the code in Google Colab, so I could use their T4 GPU
I upgraded my Huggingface Transformers library to 4.42.2 for Gemma-2 capability (pip install -U transformers in a notebook cell or transformers==4.42.2 in requirements.txt)
The outputs generated by the model were being cut off in the middle of the first or second sentence. This was because max_new_tokens in the .generate() function by default is set to 20, and needed to be set much higher (learn more here).
I tried to move the code across to HuggingFace Spaces, and learned about needing to use the @spaces.GPU decorator around the function(s) using .generate() to make them use a GPU (learn more here). However, then I realised only those paying for PRO can use this. So, back to Google Colab I went.
Eventually, I found the code below — if you’re patient — will create a chat interface in Google Colab (or, with a GPU, on HuggingFace Spaces) and allow you to interact with Gemma 2 (fine-tuned for instruction) (gemma-2-9b-it).
import gradio as gr
import torch
import numpy
# login to use Gemma in HuggingFace Spaces - after access has been requested and granted for your account
from huggingface_hub import login
import os
login(os.getenv('LOGIN_TOKEN'))
# load Gemma 2
from transformers import AutoTokenizer, AutoModelForCausalLM
gemma_tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b-it")
gemma_model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2-9b-it",
device_map="auto",
torch_dtype=torch.bfloat16
)
@spaces.GPU
def promptGemma2(textprompt, max_tokens):
input_ids = gemma_tokenizer(textprompt, return_tensors="pt")
outputs = gemma_model.generate(**input_ids, max_new_tokens=max_tokens)
return gemma_tokenizer.decode(outputs[0])
def aiChat(user_input, history):
prompt = "Answer the following prompt in a maximum of 3 short sentences: "+user_input
output = promptGemma2(prompt, 1048)
return output
demo = gr.ChatInterface(fn=aiChat, title="Model: google/gemma-2-9b-it")
demo.launch()
A response takes around 1 and a half minutes to generate in Google Colab. Without pre-pending to the submitted prompt the requirement that Gemma 2 “Answer[s] the following prompt in a maximum of 3 short sentences“, it takes over 6 minutes to be returned. These responses seemed correct, coherent, and not dissimilar to something output by ChatGPT, albeit with a less engaging tone.
In HuggingFace Spaces a result is never returned (25 min+).
Why doesn’t Gemma-2-9B-it work in my HuggingFace Space?
With a free HuggingFace Space, I have access to 2 vCPU (virtual CPUs) and 16GB of RAM (memory). The vCPUs handle computation tasks, while the RAM is used for simpler tasks like managing the application as it runs. The 2 vCPUs are likely capable of handling only 2 threads at a time, and conducts computations sequentially (rather than in parallel), altogether resulting in slow processing and long inference times.
The Gemma 2 model I am using has 9 billion parameters (gemma-2-9b-it). This is simply too large a model (requiring too many complex computations) to function fluidly on the free resources provided by HuggingFace. A smaller model (less parameters) would have a better chance of working on this infrastructure.
(Note: as of writing, the 2B parameter Gemma-2 model is not publicly available on HuggingFace but is rumoured to be coming soon. This may be small enough.)
Why does it work in Google Colab?
On Google Colab (free), I have access to a T4 GPU resource. Specifically, 15GB GPU RAM (alongside 12.7GB System RAM). GPUs are designed for simultaneously processing thousands of computations in parallel. Programs can be optimised for this hardware by employing algorithms or processes which break tasks into smaller independent subtasks to be simultaneously processed by the GPU. Many machine learning techniques, particularly in deep learning (neural networks), rely heavily on large matrix operations, which can be broken into these smaller independent subtasks. Therefore, GPUs are highly beneficial for machine learning tasks, which require thousands of similar calculations to be processed quickly.
This GPU is the most notable reason Gemma 2 9B works on Google Colab, and the model struggles on HuggingFace Spaces (no GPU). While inference is non-instantaneous due to the resources being only just enough for the model to load and respond — the model does at least return an output!
Additionally, I think pre-pending to the user submitted query the requirement that the model responds in 3 sentences or less aids inference performance slightly. This reduces the total number of tokens needing to be generated and returned by the model. On the other hand, it’s an additional requirement for the model to consider and may lead to more computations. Without this requirement, the model takes ~6 minutes to return a (much longer) response.
What are the downsides to Google Colab, then?
While these provided resources are substantially better than HuggingFace Spaces, they may still be limiting for some users. For my applications, however, I’ve found them to be just enough for my needs.
The more annoying limitation imposed in the free version is the time limit. While Google notably “does not publish these limits” (read more here), people online measure it as being limited to approximately 1 hour of use per 24 hours.
That all being said, I obviously understand why all these limits exist etcetera etcetera money etcetera…
Improvements to make
I am eager to swap into my code the 2 billion parameter version of Gemma-2 when (if?) it is released. I suspect the drop from 9 billion parameters to 2 billion will allow for faster inference in Google Colab. Whether that drop will be enough to get it running in HuggingFace Spaces is to be determined.
In the meantime, I might try out a few other open instruction fine-tuned LLMs. The specific model I use for my eventual application isn’t important.
I also want to fully code-out my application idea, which stems from my prior AI-interaction experiences. When interacting with models like ChatGPT or Claude 3.5 Sonnet (which I quite like), I’ve often desired an additional text box to paste notes for the AI to consider throughout the conversation. I can remember interacting with ChatGPT in the past and it forgetting important details I’d passed it earlier in the interaction (because those items fell out of its limited context window).
I think an additional text input where I can leave notes for the model to consider for every prompt could help aide in this issue. It would also provide a dynamic edge to the experience where if I change some values in this context text box, the model should “forget” about what was in there and only consider the new information. And, with model context windows steadily increasing, my previous worries about exceeding their limits with too many notes have been mostly nullified.
I do however feel like I may be racing the AI conglomerates to get this feature complete. It appears Anthropic (Claude) might have rolled out a similar feature for their premium members this week (read their blog post here).
Thank you for reading :)