
Medusa: Multiple Decoding Heads for Faster LLM Inference
Enhancing existing LLMs with multi-token prediction


In this post:
MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Paper Highlights
The problem
Their solution: Medusa
Methodology
What are Medusa heads?
What is tree attention?
Speculative decoding
Medusa-1 vs Medusa-2
Medusa loss
Other highlights & results
My Thoughts
🐍 MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Medusa seeks to improve model inference speed by adding additional decoding heads to existing LLMs. These additional heads enable multi-token prediction and can be trained with the backbone LLM frozen, or in conjunction with the original LLM.
Read the paper: https://arxiv.org/abs/2401.10774
Paper code on GitHub: https://github.com/FasterDecoding/Medusa
Good overview video: Paper overview video
Better partial implementation on GitHub: https://github.com/evintunador/medusas_uglier_sisters
Abstract
Large Language Models (LLMs) employ auto-regressive decoding that requires sequential computation, with each step reliant on the previous one's output. This creates a bottleneck… we present Medusa, an efficient method that augments LLM inference by adding extra decoding heads to predict multiple subsequent tokens in parallel. Using a tree-based attention mechanism, Medusa constructs multiple candidate continuations and verifies them simultaneously in each decoding step… Our experiments demonstrate that Medusa-1 can achieve over 2.2x speedup without compromising generation quality, while Medusa-2 further improves the speedup to 2.3-3.6x.
📝 Paper Highlights
The problem
Recent advancements in LLMs have come from increasing a models size (amount of parameters). The trade-off, however, has been latency when running inference.
The bottleneck in inference is caused by the auto-regressive decoding used by LLMs. During auto-regressive decoding, all the model parameters are transferred to the accelerators cache from High-Bandwidth Memory. The result of this process is the generation of only a single token — the Next Token Prediction (NTP).
To speed up this decoding process, speculative decoding has been previously suggested. Typically, speculative decoding involves using a smaller model to generate a draft of what the next few tokens should be. Then, the main model evaluates this output, and accepts it based on if it would have also generated those tokens (I will explain this process better below). However, there are many challenges with using a draft model.
Their solution: Medusa - an LLM Inference Acceleration Framework
Instead of using a draft model to generate the next few tokens from an input sequence, their paper proposed adding multiple decoding heads “at the end of” (or “on top of”) an existing backbone model.
Each of these decoding heads are trained to generate a token for a different future position of the sequence. These heads allow concurrent prediction of multiple tokens to be achieved.
Additionally, this small architecture addition can be applied to an existing LLM without the need of fine-tuning the existing model (in the case of Medusa-1, where the backbone model is frozen and only the new heads are trained). Alternatively, the original backbone model can be further fine-tuned along with these new heads to improve the accuracy of predictions (Medusa-2).
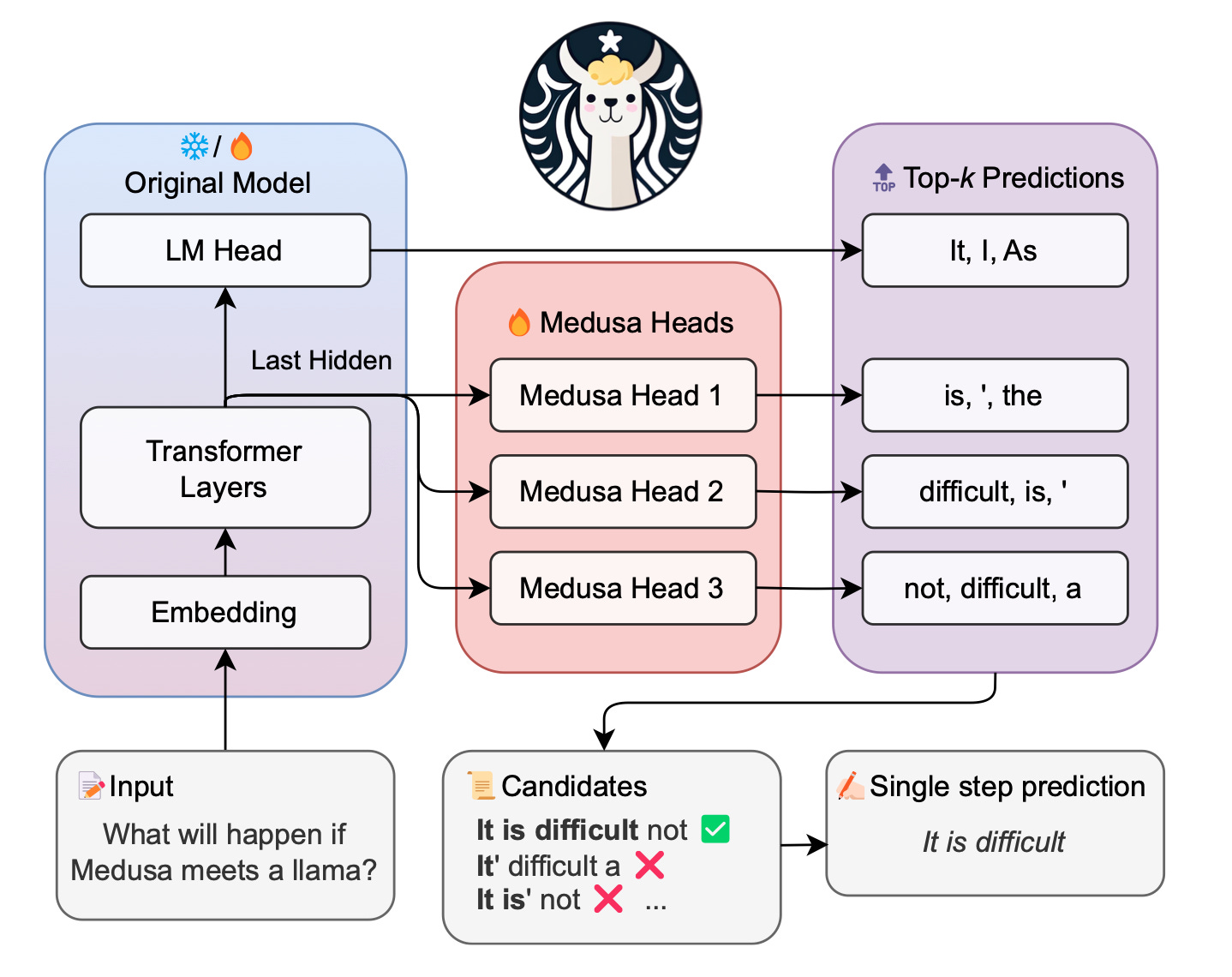
Methodology
First, candidate token predictions are generated by the “Medusa heads” (additional decoding heads at the end of the model)
These candidates are then processed using tree-attention as proposed by this paper.
Finally, the candidates are evaluated by the model and one is selected to continue the generation from.
What are Medusa heads?
“Medusa heads are additional decoding heads appended to the last hidden states of the original model.” In training, each head learns to generate probabilities for a different future token position.
For example, take an input sequence: ABCD
The original head will generate for the 5th position: E
The first medusa head will learn to generate, from the same input sequence, the 6th position token prediction: F. It will not know what the original head generated.
The second medusa head will learn to generate the 7th token position prediction: G, without knowing what the previous heads generated.
And so on…
Each head is “a single layer of feed-forward network with a residual connection". They found this to be satisfactory.
What is tree attention?
With the use of K Medusa heads, the next K+1 token predictions are generated in a single pass through the model.
(+1 because the model’s original final decoding layer is counted separately by the authors)
Remember that for each head K these predictions cover the entire vocabulary. So, for each head, the top Sk predictions can be considered in conjunction with the top Sk predictions from the other heads.
The value of S can be set independently for each head. The top 3 predictions for the first Medusa head could be considered in combination with the top 2 predictions for the second Medusa head, and so on.
This can be visualised in a tree, as seen below. Therefore, a tree-based attention mechanism is required.
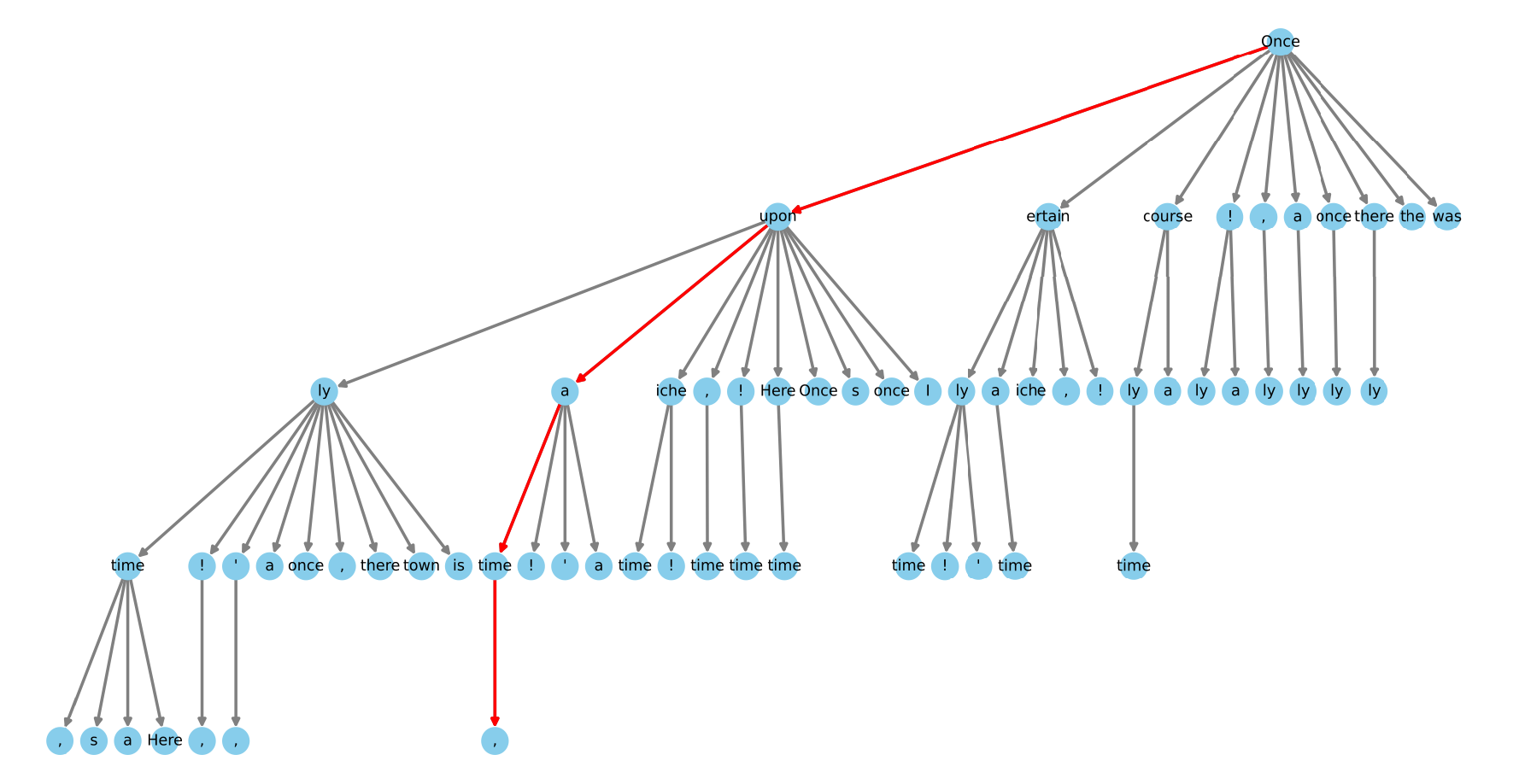
The prediction candidates are evaluated concurrently with a tree-based attention mask hiding tokens from other branches and nodes from view.
Verifying candidates with speculative decoding
The paper suggests using speculative decoding (rejection sampling) or their proposed “typical acceptance” scheme. I’m going to focus on speculative decoding since I think it’s pretty cool!
It is first important to *really* understand the autoregressive nature of Transformers. When a sequence is passed into the model (say, ABCDEF), you get the next token prediction out (G). However, unless a KV Cache is being used, the model is also always generating predictions for all of the tokens in a sequence.
It is re-looking at A and generating predictions (B, D, N)
It is re-looking at AB and generating predictions (C, A, E)
It is re-looking at ABC, …, ABCDE
It is looking at ABCDEF and generating the new next token prediction (G)
(The predictions made when looking at A,…,ABCDE are ignored)
What of a waste of processing, right?
(This is, to my understanding, why KV caches are helpful)
However! This property can be harnessed for multi-token prediction, such as with Medusa.
Say you input the sequence ABCDEF.
The model head predicts G
The first Medusa head predicts H
The second Medusa head predicts I
The third Medusa head predicts Z (oh no!)
The fourth Medusa head predicts K
Take the single candidate created by this prediction: ABCDEFGHIZK
Input this sequence to the model, and consider this time the concurrent predictions the model makes for every position in the sequence.
The model sees ABCDEF and predicts G ✅
The model sees ABCDEFG and predicts H ✅
The model sees ABCDEFGH and predicts I ✅
The model sees ABCDEFGHI and predicts J, whereas the head predicted Z ❌
(Remember: the original Medusa head only had the input sequence ABCDEF to make it’s prediction off)
Well, the model head and the first two Medusa heads predictions matched! But, the third Medusa heads prediction was different. So, we shorten the sequence to the last matching position (ABCDEFGHI) and restart the prediction process.
This results in faster inference (assuming the Medusa heads are at least sometimes right), due to less passes through the model.
This demonstrates how speculative decoding is used to evaluate a single candidate prediction. This is further applied across the entire tree, with the longest matching candidate being selected to be resubmitted as input and progress the text generation.
Medusa-1 vs Medusa-2 overview
The Medusa-1 framework involves freezing the backbone model and only fine-tuning the additional Medusa heads.
The Medusa-2 framework can be used when the training dataset of the original model is known (and public). The entire model, backbone included, can be fine-tuned using the original training dataset, in order to best teach the Medusa heads to generate future tokens accurately.
Medusa Loss
To teach the additional Medusa heads to generate accurate predictions for future tokens, Medusa loss is used.
In normal cross-entropy loss, the accuracy of a models prediction for the next token, from some input sequence, is evaluated in comparison with the ground truth (true) token.
(In reality it’s the probabilities over the entire vocabulary for what the next token will be, compared with the true probabilities — not token to token)
For Medusa, cross-entropy loss is modified to include the additional K Medusa heads. For each head, for some input sequence of length N, the K-th Medusa head generation prediction is compared with the N+K+1 position ground truth token for that sequence. The losses from each head are summed to result in the final Medusa loss.
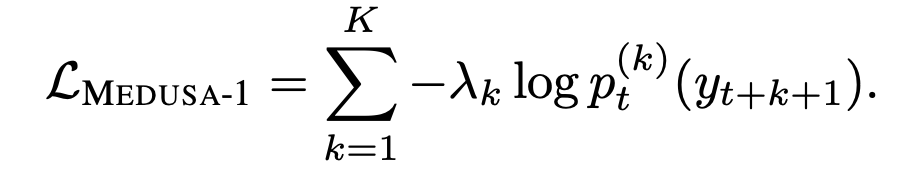
The loss was seen to be larger as the number of Medusa heads increased. This is understandable as the predictions made further ahead in the sequence by the latter Medusa heads are more likely to be inaccurate. To combat this, a weight was added to balance the loss from different heads.
In Medusa-2, the Medusa loss is further combined with the original models loss to maintain the original models NTP capability.
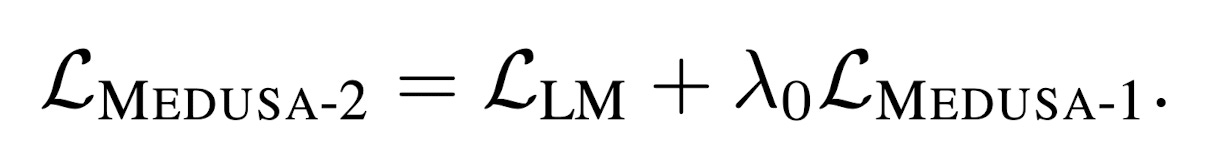
Other highlights:
When training Medusa-2, using seperate learning rates for each head could improve performance and help address the poor predictions proposed by latter heads.
Medusa heads have a large loss at the beginning of training (Medusa-2), which could distort the backbone models parameters. They suggest “warming up” the Medusa heads by first training only the heads (like in Medusa-1), and then training again both the Medusa heads and the original model.
They found 5 heads to be sufficient in most of their cases. Sometimes three or four heads were enough when the tree attention was optimised.
Results
They achieved significant speedups on inference when adding Medusa heads to existing 7B parameter LLMs. The best speed-ups were observed when Medusa heads were added to coding LLMs.
💭 Thoughts
I had to spend a few months slowly trying to understand speculative decoding, and how it can be used by frameworks like Medusa to speed-up inference. I feel somewhat comfortable with the idea now — and I think it’s quite promising!
I like how Medusa can theoretically be simply added to any existing LLM, and supposedly leads to huge inference speed-ups. Additionally, the paper made claims about fine-tuning Medusa heads added to large LLMs on a single GPU. Anything that inches model use and development close to my MacBook has my approval.
I would not be surprised if multi-token generation techniques, like Medusa (and Facebook’s method I wrote about previously) were being secretly used by some of the top AI companies in their model development. To me, it feels like an under-explored area of AI research with possible applications in many other fields where Transformers are used. Or maybe I just have rose-coloured glasses on. Time will tell.
: )